To test some popular playoff axioms, I used ordinal logistic regression to estimate the probability that a team would win a given postseason series (in 4, 5, 6, or 7 games) or lose it (in 4, 5, 6, or 7 games). I examined the period from 2003 to 2017 during which the playoffs consisted of four rounds of seven-game series. For explanatory variables, I compared each team’s regular season performance with that of their playoff opponent. I evaluated the predictive power of various regular-season team stats based on model fit using cross validation.
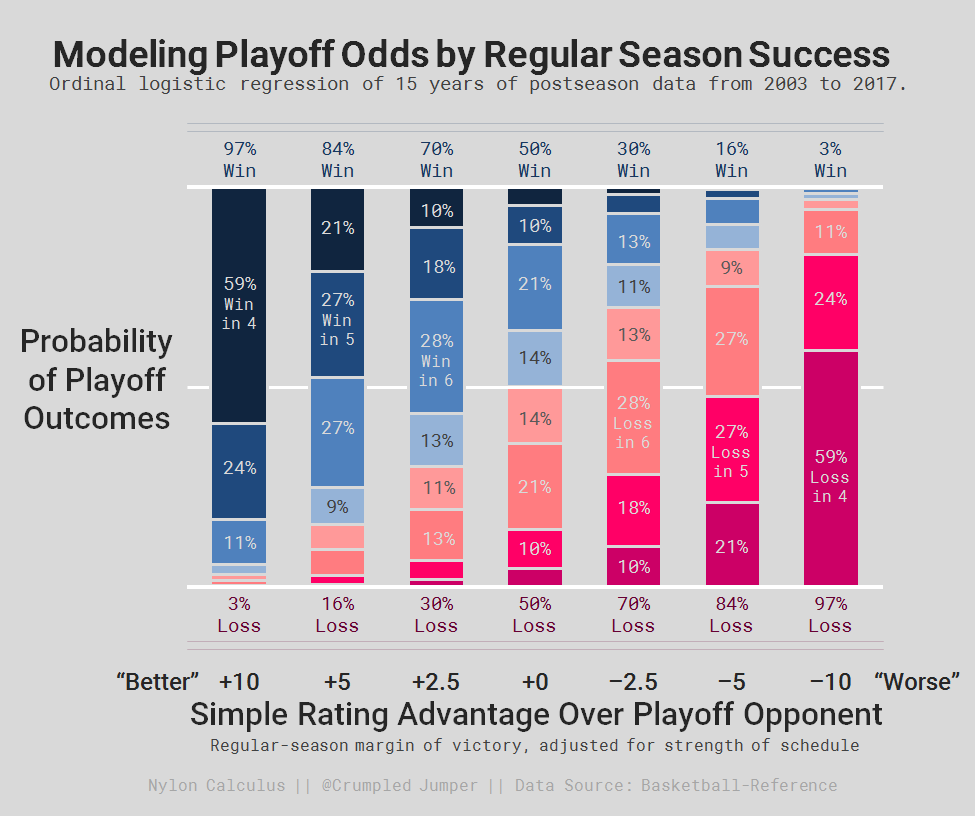
After accounting for team quality, most of the regular-season stats I evaluated — pace, 3-point attempt rate, defensive rating — had negligible influence on postseason series outcomes. On the other hand, it did seem to help somewhat to have LeBron James on your team, though.


Is there an ideal way to distribute star power up and down a roster? Would three Betas be just as good as an Alpha-Beta-Gamma? To find out, I examined the history of NBA teams since 1980 in search of the ideal talent distribution for a championship roster. I used hierarchical clustering (hclust function in R) to group rosters with similar talent distributions.
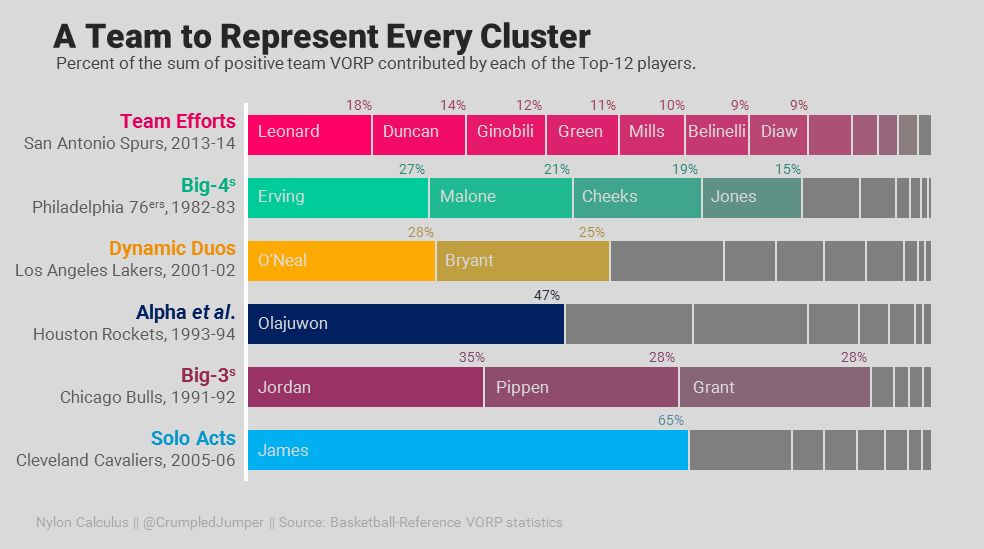
Then I modeled the probability of winning a championship based on regular-season team quality and talent-distribution group.

I found that, for a given level of overall team quality, an unbalanced roster was more likely to produce a championship than a balanced one.
For FiveThirtyEight I modeled NCAA tournament wins based on a team’s seed and KenPom net ratings and then looked at historic underachievement by good teams who played at a slow pace. The graphics team helped me illustrate the impact of pace on teams expected to win two games or more.

Check out more useful projects.
